

摘要:最新的手机号正则用于识别与验证手机号,采用最佳实践方法。该正则表达式能够准确匹配各种格式的手机号码,包括固定长度和可能的前缀和后缀。通过验证手机号的格式,确保输入的数据符合规范,提高数据质量和用户体验。该正则表达式的应用广泛,适用于各种编程语言和框架,确保手机号的准确性和有效性。
本文目录导读:
随着移动互联网的普及,手机号码已成为人们日常生活中重要的联系方式,在各类应用系统中,手机号的验证与识别显得尤为重要,本文将介绍如何使用最新手机号正则表达式进行手机号的验证与识别,以确保用户输入的手机号码符合规范。
手机号验证的重要性
手机号验证是保障信息安全的重要一环,通过验证用户输入的手机号码是否合法,可以有效防止恶意注册、垃圾信息发送等情况,对于涉及用户隐私和资金安全的应用,手机号验证也是确保用户身份真实性的重要手段。
手机号正则表达式的演变
随着手机号码政策的不断变化,手机号码的编号规则也在不断更新,手机号正则表达式需要与时俱进,以适应最新的手机号码规则,近年来,手机号码的编号规则主要包括:
1、固定电话与手机号码的合并:随着手机号码的普及,部分地区的固定电话与手机号码实现合并,使得号码规则更加复杂。
2、新增号段:随着通信技术的发展,手机号码号段不断新增,如130、159等,部分地区的手机号码还可能包含特殊号段,如虚拟运营商号段等,正则表达式需要涵盖这些新增号段和特殊号段。
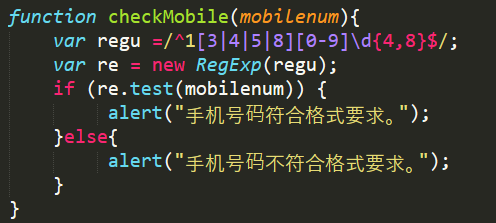
最新手机号正则表达式的构建
针对最新的手机号码规则,我们可以构建如下的手机号正则表达式:

^(13[0-9]|14[0-9]|15[0-9]|16[0-9]|17[0-9]|18[0-9]|19[0-9])\d{8}$解释如下:
^ 表示匹配字符串的开始位置;
(13[0-9]|...) 表示匹配以不同号段开头的手机号码;其中[ ] 表示匹配方括号内的任意一个字符;| 表示或者的意思;\d 表示匹配数字;{n} 表示匹配前面的子表达式恰好 n 次;\d{8} 表示匹配连续的八个数字;
$ 表示匹配字符串的结束位置,该正则表达式可以匹配以中国大陆为主的手机号码,如果需要匹配全球范围内的手机号码,可以根据不同国家和地区的手机号码规则进行相应的调整,请注意该正则表达式仅适用于普通手机号码的验证,对于特殊号段如虚拟运营商号段等可能需要额外处理,该正则表达式仅适用于静态验证,对于动态变化的手机号码规则可能无法完全覆盖,因此在实际应用中需要根据具体情况进行调整和优化,还需要注意的是,正则表达式虽然可以用于手机号的验证和识别,但并非万能之策,在实际应用中还需要结合其他手段如后端验证、数据库查询等方式进行验证以确保数据的准确性和安全性,同时还需要关注手机号码政策的动态变化及时更新正则表达式以适应新的规则变化,此外还需要关注手机号的格式化和存储问题以确保数据的完整性和可读性,对于格式化问题可以采用常见的格式如国际电话号码格式进行存储和展示以便于用户阅读和理解同时方便后续的数据处理和分析,总之在使用最新手机号正则表达式进行手机号验证和识别时需要综合考虑多种因素以确保系统的稳定性和用户体验的提升,五、总结本文介绍了最新手机号正则表达式的构建方法和应用场景以及在实际应用中需要注意的问题,通过合理使用正则表达式可以有效提高手机号验证和识别的效率和准确性从而保障系统的信息安全和用户隐私权益,同时在实际应用中还需要结合其他手段进行综合验证以确保数据的准确性和安全性,随着移动互联网的不断发展手机号的验证和识别技术也将不断更新和完善以满足不断变化的市场需求。
 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...